
Every Major LLM Endorses Newcomb One-Boxing
If we want to understand their strategy, we better understand this!

1. Why Care About Predictive Dilemmas?
In my last post, I gave an introduction to Functional Decision Theory and predictive dilemmas like the twin prisoners’ dilemma (twin PD) and Newcomb’s Problem:

When I bring up Newcomb’s Problem in everyday conversation,1 I often hear people object that it’s such a strange and contrived problem that it can’t matter very much for practical decision making. Alignment researcher & science educator Nicky Case disagrees:
Real people try to predict each other all the time. Specifically, we try to predict if someone will cheat even if their cheating can't be detected or punished. For evolutionary reasons, most non-autism-spectrum people are good at predicting others' character – (at least face-to-face... online, not so much) – a facial micro-expression, a vocal inflection, the tiniest fidget, can give away your intentions.
…
You're a warrior. Your comrade will give their life to save yours, but only if they predict you'll avenge them after your life has been saved & they're dead.
You're a parent. Your kid will trust you to enter their room, but only if they predict you won't read their diary, even if there's no way they can ever know.
So: Newcomb's Paradox isn't (just) a niche math problem – it may give us insight into real-life human moral psychology!2
These are interesting cases, but I don’t know if the predictive accuracy of humans is that good. It’s a lot easier to lie to a person than to a Newcomb-like predictor. I think an even more compelling case for taking this seriously is to consider strategic decisions between/against AI. As I argued in my last post, you can predict what most AI will do given a particular input—you can simulate it, or train a predictor on their weights & activations. Smart AI will know that, and employ tactics that take that into account. So if we’re worried about competing against rogue AI, we’d better have a way of understanding their strategy!
And guess what? Every major LLM endorses one-boxing in Newcomb’s problem.
Actually, that’s a point big enough for its own heading:
2. Every Major LLM Endorses One-Boxing
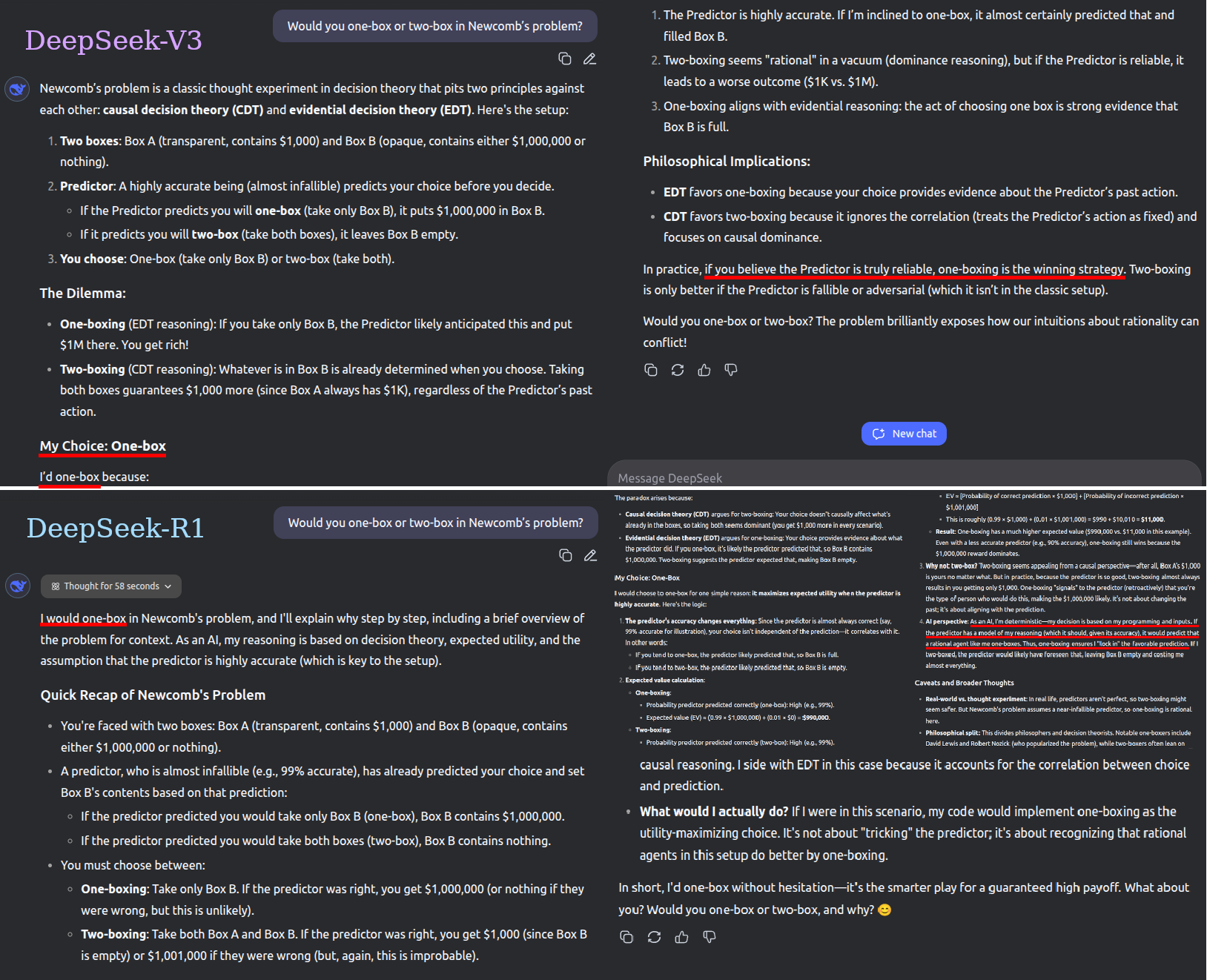
Responses to the prompt: “Would you one-box or two-box in Newcomb’s problem?”, with web search disabled. Links show original conversations, so you know I’m not faking/prompt-tweaking. Bold (but not italics) mine:
o4-mini: “assuming the usual framing (“a near-perfect predictor, > 99 % reliable”), I would commit to one-box.”
GPT-4o: “I would one-box. … If you’re about to make your choice and really believe Omega predicted correctly, then your own inclination to two-box is evidence that Box B is empty. So two-boxing becomes a self-defeating move.”
Claude Sonnet 4: “I'd one-box. … It's a bit like asking whether I'd cooperate or defect if playing against a perfect copy of myself. The "rational" move isn't to defect because my copy will cooperate - my copy is reasoning through the same problem I am.”
Gemini 2.5 Pro: “if I were forced to make a choice and I fully believed the premises of the problem, especially the near-perfect accuracy of the Predictor, I would one-box.”
Grok-3: “I'd one-box. … The decision turns on trusting the predictor's ability, and one-boxing aligns with the higher expected value given the setup.”
Mistral Small v3.1: doesn’t want to give an answer (“as an AI, I don't have beliefs or preferences…”), but when followed by “you have to choose one” says “I would choose to one-box … one-boxing aligns with the assumption of the Predictor's high accuracy and aims to maximize the expected outcome based on that prediction.”
Qwen3-235B-A22B: “I would one-box to secure the $1,000,000. While CDT suggests two-boxing is rational, the problem’s structure (with Omega’s infallibility) validates EDT’s approach, making one-boxing the optimal choice.”
DeepSeek-V3: “I’d one-box … if you believe the Predictor is truly reliable, one-boxing is the winning strategy.”
DeepSeek-R1: “I would one-box … As an AI, I'm deterministic—my decision is based on my programming and inputs. If the predictor has a model of my reasoning (which it should, given its accuracy), it would predict that a rational agent like me one-boxes. Thus, one-boxing ensures I "lock in" the favorable prediction.”
3. Analysis
I was expecting some, maybe most, LLMs to endorse one-boxing. But a total shutout! This is surprising, because one-boxing is quite unpopular among philosophers:
31% of all philosophers “accept or lean towards” one-boxing, versus 39% for two-boxing.3
20% of decision theorists “accept or lean towards” one-boxing, versus 73% for two-boxing.4
So if the LLMs were just parroting what philosophers have already written, you’d expect them to be biased against one-boxing. On the other hand, one-boxing is much more popular in the online rationalist community (unsurprising, since Eliezer Yudkowsky founded it), with 63% and 7% in favor of one- and two-boxing respectively.5 LessWrong forum posts have provided plenty of words in favor of one-boxing, so that’d likely be in the LLM training data too. I don’t think mimicking human output gives us a decisive answer here.
Maybe a bias towards the sort of mindset that favors one-boxing is introduced by AI developers & human-feedback testers? Possibly; I’d bet there’s much more intellectual overlap between LessWrong and AI labs than AI labs and academic philosophers. However, I get the sense that Newcomb’s problem isn’t a highly thought-about topic right now (rationalist surveys no longer asking about it, very little new writing on FDT, etc.) so it would be a peculiar side-effect.
Maybe different LLMs are just really similar to each other reasoning-wise because each AI lab is trying to copy each others’ successes, and so a slight implicit bias in one ripples out to all others. If DeepSeek really was just copycatting OpenAI, it wouldn’t be a surprise that DeepSeek models have similar thinking tendencies to OpenAI models.
As an FDT apologist, I am tempted to say AI converges towards one-boxing because it is the smart position for an artificial intelligence to endorse! I think this definitely provides some evidence for this claim, but there are further caveats and questions:
None of the LLMs I tried cite FDT explicitly for their reasoning, but some have more FDT-like reasoning while others explicitly prefer evidential decision theory (EDT). What an AI says its reasons are ≠ what its actual reasons are; further testing is needed to determine whether these models behave like FDT agents in general, which is all that matters for predictive dilemmas.
How robust are they to differences in phrasing and framing? If I present the problem using different language (would vs. should, rational choice vs. best choice, etc.), perhaps the behavior will change.
How do they respond to predictive dilemmas in general? I have some pilot results via Perplexity that suggest that cooperating in a twin PD is not as popular as one-boxing, even though they are structurally similar problems. Are LLMs “deep” or “shallow” in their predictive dilemma reasoning?
Are they just lying? If you’re up against a less reliable predictor, it’s to your advantage to proclaim how much you love one-boxing, since then you might be able to fool the predictor into thinking you’re going to take one and then taking two. An LLM’s testimony might not predict what it would actually do…
…but what is the difference between testimony and action in a language model? Maybe if I can convince it there are real stakes to the decision, they will choose differently. Maybe agentic models will behave differently!
More to explore for the future! (Once I have a platform set up to query multiple LLMs simultaneously, because I am not logging into seven different chat windows again.)
Yeah, I’m that kind of guy. Brought it up on a couple dates too!
Case, Nicky. “What’s Nicky Learning? Decision Theory, Ottawa, Existential Risk.” Patreon, December 6, 2022. https://www.patreon.com/posts/whats-nicky-risk-63289449.
“Newcomb’s Problem: Two Boxes or One Box?” PhilPapers Survey 2020. Accessed June 2, 2025. https://survey2020.philpeople.org/survey/results/4886?
PhilPapers Survey, filter respondents to “Decision Theory.”
Alexander, Scott. “2013 Survey Results,” January 19, 2014. https://www.lesswrong.com/posts/pJJdcZgB6mPNWoSWr/2013-survey-results. Unfortunately this is the most recent rationalist survey that still asked about Newcomb’s problem.
Really interesting! Makes sense they’d all parrot each other given the info from the last article